Working with Mercurial
Prerequisites
QuickBuild utilizes the Mercurial command (hg) to interact with remote Mercurial repository. If this command is not in system path, you will need to specify location of the command by configuring Mercurial plugin as below:
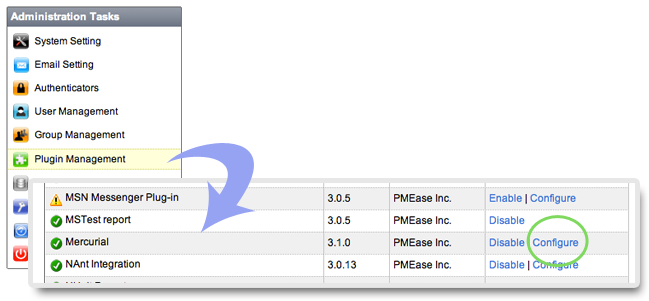
Further more, Mercurial command (hg) location can be specified on a per-node basis by following below steps:
-
Open Mercurial plugin setting page and define the hg path property as:
${node.getAttribute("hgPath")} -
For each node that does not have hg on system path, define the user attribute hgPath to point to the actual Mercurial path like below:
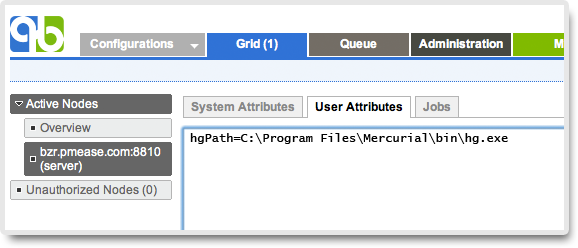
NOTE: example above is just for demonstration, you can use any other user attribute name instead of hgPath.
Creating a Mercurial Repository
You may refer to this page on how to add a repository.
Supported URL prefixes
Currently, below URL prefixes are supported:
- [local/filesystem/path]
- [file://local/filesystem/path]
- [http://host\[:port\]/path\]
- [https://host\[:port\]/path\]
- [ssh://host[:port]/path]
If https is used, and your credential need password, you need first add the credential manually to the nodes which you want check out code to.
If ssh based URL is used, please use public key without password for authorization and you need not specify the password when you create the repository. You can reference your SSH manual on how to create public key without password.
Proof build support
Your developers might need to push their local commits in local branches to a central official Mercurial repository occasionally. In this case, QuickBuild can validate these outgoing changes by running proof build before pushing them.
Test proof build as administrator
Since proof build set up is a bit tricky, we first set up proof build for the administrator account and make sure it works before we proceed to enable it for all developers. To set up proof build for administrator, please follow below steps:
- Login as administrator and download user agent by switching to My tab.
- Install and start user agent on your own desktop. For testing purpose, please start the agent as a foreground process. On windows, this can be done by running agent.bat ; on Unix platforms, this can be done by running agent.sh console
- Set up a test configuration on QuickBuild server, define a Mercurial repository, enable the proof build option in advanced section like below:
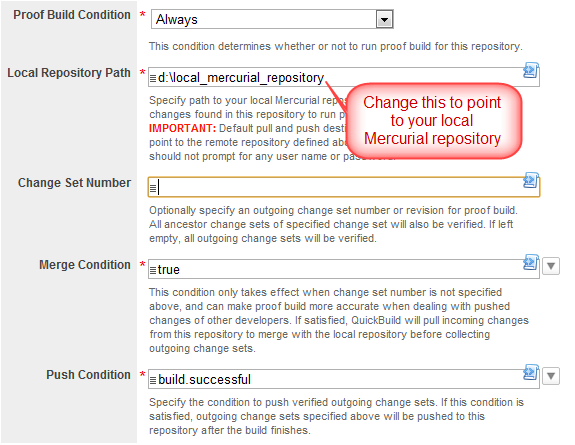
- Make sure the hg command exists in the system path of both server machine and your desktop. If not, please follow the prerequisites section to tell QuickBuild location of hg command.
- Add a repository/checkout step into step execution graph and have it checkout from the repository defined above.
Now proof build has been enabled for your account, please make some local commits into your local repository specified above, and then run the test configuration. If set up correctly, your local commits will be picked up and reflected in the build result. A local change tab will also appear to display local commits after build finishes. Your local commits will be pushed automatically if build is successful.
Enable proof build for all developers
Now that we have a concept of how proof build works. In order to get proof build works for all developers, we need to parameterize various proof build properties, so that different properties can be used for different developers. To do this, you will need to:
-
Define configuration variables like below:
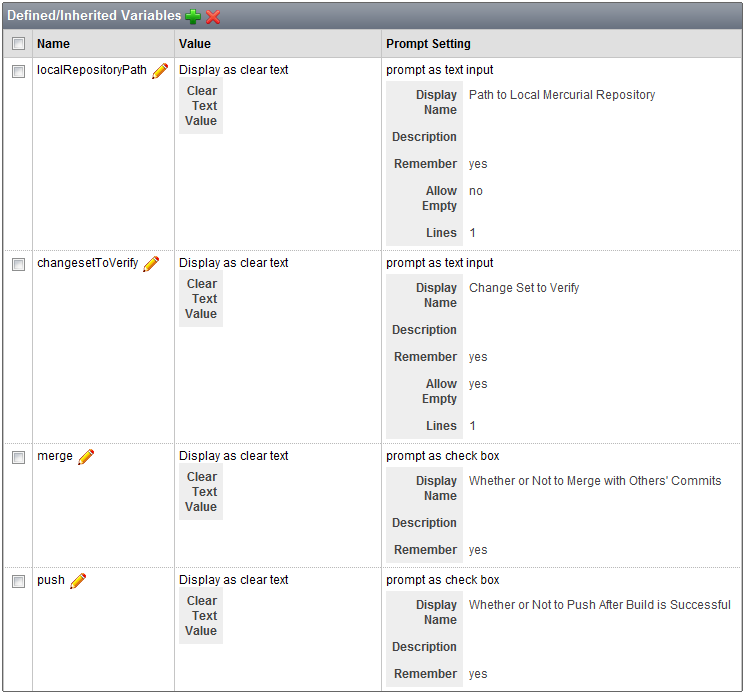
-
Script various properties in proof build section to make use of above variables like below:
Property Name Property Value Local Repository Path ${vars.get("localRepositoryPath")} Change Set to Verify ${vars.get("changesetToVerify")} Merge Condition vars.get("merge").asBoolean() Push Condition build.successful && vars.get("push").asBoolean() In this way, various proof build properties will be prompted when your developer runs the build. Once they've been specified by your developer for the first time, the values will be remembered for subsequent triggers for that user.
At last we suggest to set up the configuration to enable concurrent builds so that multiple builds in the same configuration can run concurrently. This is vital to get fast feedback in case multiple developers are requesting proof builds in the same time.